Le stockage de données ne se résume pas à ajouter des disques dans un serveur. Il faut aussi penser à la vitesse d’accès, à la redondance, à la sauvegarde, à la durée de conservation et à la manière dont le réseau transporte les informations. Dans cet article, je passe en revue les supports les plus utiles, les architectures réseau les plus courantes et les critères concrets qui permettent de choisir une solution fiable sans surpayer ni sous-dimensionner.
Les repères utiles pour choisir une architecture de stockage sans se tromper
- Le bon support dépend de l’usage : un SSD, un NAS, une bande ou un stockage objet ne répondent pas au même besoin.
- Le réseau compte autant que le disque : latence, débit et protocoles changent directement les performances.
- La sauvegarde n’est pas la redondance : un RAID protège d’une panne, pas d’une suppression ou d’un ransomware.
- La règle 3-2-1 reste la base : 3 copies, 2 supports différents, dont 1 hors ligne ou isolée.
- La conservation doit être bornée : pour les données personnelles, on définit une durée utile et on archive seulement ce qui est justifié.
Ce que recouvre vraiment la conservation numérique
Je distingue toujours trois choses que l’on mélange trop souvent : le stockage actif, la sauvegarde et l’archivage. Le stockage actif sert au travail quotidien, la sauvegarde sert à revenir en arrière après un incident, et l’archivage sert à garder une information utile mais peu consultée, parfois pour des raisons légales ou probatoires.
Cette distinction change tout, parce qu’un même jeu de données ne doit pas vivre sur la même couche selon sa valeur métier. Une base de production, une copie de secours et un historique réglementaire n’ont ni la même fréquence d’accès, ni la même tolérance à la latence, ni la même politique de suppression.
Pour les données personnelles, la logique est encore plus stricte : on ne conserve pas indéfiniment. La CNIL rappelle par exemple qu’un candidat non retenu est généralement conservé au plus 2 ans, qu’un bulletin de paie se garde 5 ans et que certaines factures doivent être conservées 10 ans. Autrement dit, la question n’est pas seulement “où stocker ?”, mais aussi “combien de temps, pour quelle finalité et avec quel niveau d’accès ?”.
Une fois cette hiérarchie posée, le choix du support devient beaucoup plus lisible.
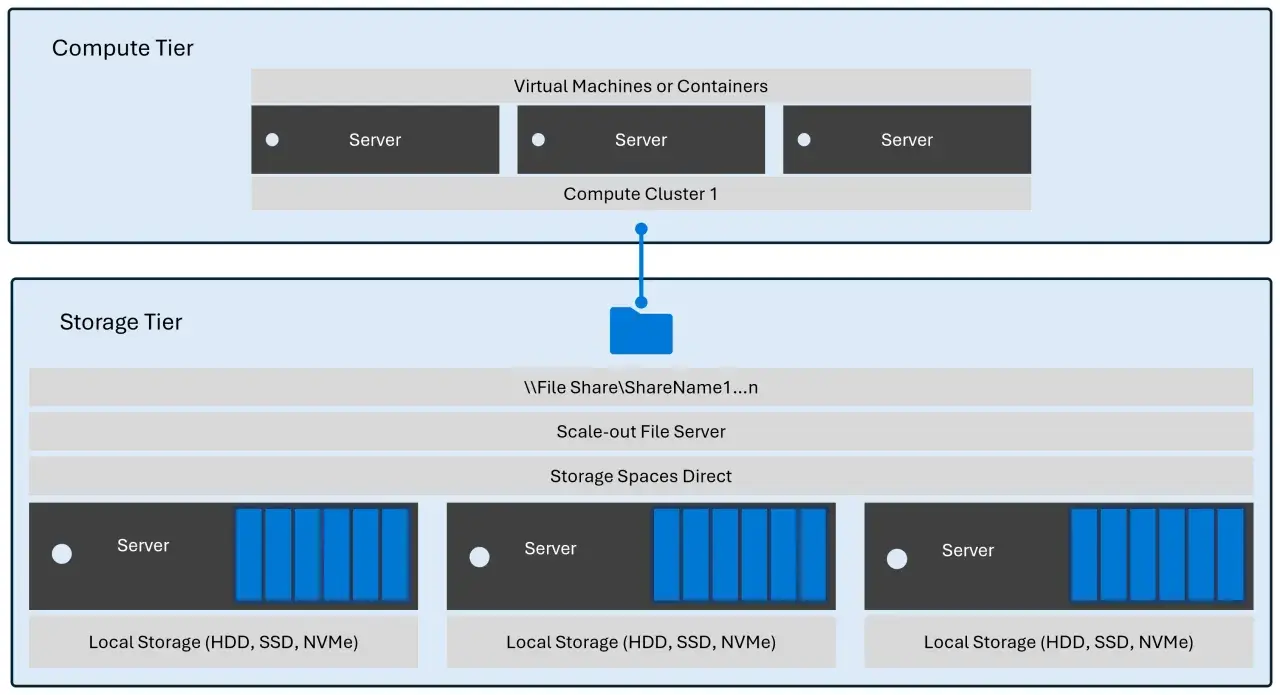
Les supports qui comptent vraiment selon le besoin
Quand on parle de supports, je pense à la fois au média physique et à la logique de service. Un disque, un ensemble RAID, un NAS, un stockage objet ou une bande magnétique ne servent pas la même chose, même s’ils répondent tous à un besoin de conservation des informations.
| Support | Points forts | Limites | Quand je le privilégie |
|---|---|---|---|
| HDD | Grande capacité, coût par téraoctet plus bas, pratique pour accumuler beaucoup de fichiers | Latence plus élevée, pièces mécaniques, performances plus modestes | NAS de capacité, sauvegardes secondaires, volumes peu sollicités |
| SSD | Temps d’accès très faible, bonnes IOPS, idéal pour les accès répétés et simultanés | Plus cher à capacité égale | Bases de données, machines virtuelles, postes de travail exigeants, traitements actifs |
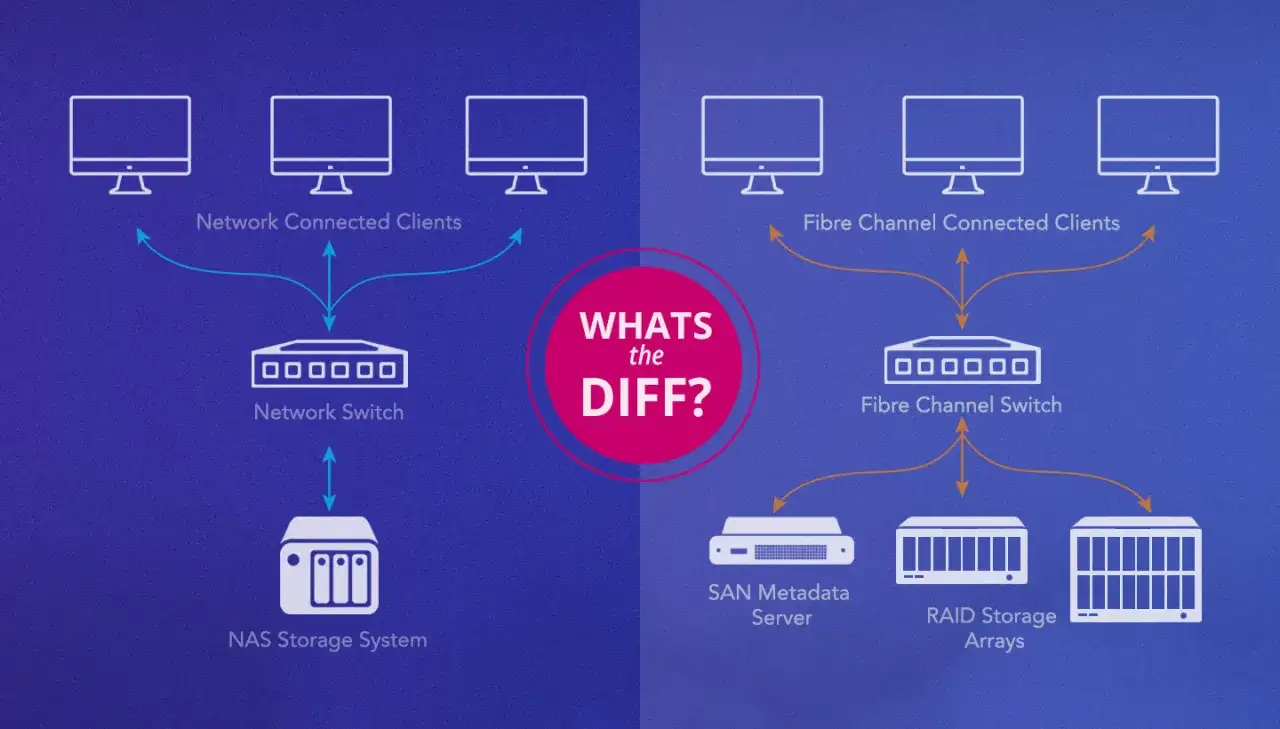
| NAS | Partage simple, accès au niveau fichier, intégration facile dans un réseau local | Peut saturer si plusieurs flux lourds se croisent | Documents partagés, dossiers d’équipe, médias légers à moyens |
| SAN / bloc | Volumes rapides, faible latence, bon contrôle pour les applications critiques | Architecture plus technique à administrer | Virtualisation, bases transactionnelles, applications sensibles aux IOPS |
| Stockage objet | Très grande échelle, métadonnées utiles, bon pour les données non structurées | Moins naturel pour les usages de type dossier partagé | Photos, vidéos, journaux, jeux de données, archives cloud, sauvegardes long terme |
| Bande magnétique | Excellent pour l’archivage hors ligne, coût maîtrisé sur la durée, isolation physique | Restauration lente, usage moins souple | Rétention légale, copie air gap, reprise après sinistre, archives froides |
Je vois souvent un contresens : le RAID est pris pour une sauvegarde. Ce n’est pas le cas. Il améliore la tolérance à la panne locale, mais il ne protège ni d’une suppression humaine, ni d’un cryptage malveillant, ni d’une corruption logique. Pour de vrais enjeux de disponibilité, il faut superposer les couches plutôt que compter sur un seul mécanisme.
Ce panorama des supports n’a de sens que si l’on regarde aussi la façon dont le réseau les expose aux applications.
Pourquoi le réseau change autant la qualité du stockage
Un stockage performant sur le papier peut devenir médiocre dès qu’il traverse un réseau mal dimensionné. Je regarde donc toujours trois paramètres : la latence, le débit et le nombre d’opérations simultanées. La latence mesure le temps de réponse, le débit mesure la quantité transférée, et les IOPS décrivent le nombre d’opérations d’entrée/sortie par seconde.
Dans un environnement de fichiers, le NAS expose des dossiers partagés via des protocoles comme SMB ou NFS. C’est simple à utiliser et très adapté au travail collaboratif, mais les performances restent tributaires du réseau local, du nombre d’utilisateurs et de la qualité de la baie. En bloc, la SAN présente à l’application un volume comme s’il s’agissait d’un disque ; c’est plus technique, mais très efficace pour les bases de données et les machines virtuelles. Enfin, le stockage objet s’administre par API : il est moins naturel pour les logiciels anciens, mais très robuste pour automatiser des flux massifs ou répartis.
Je résume souvent ainsi : plus la donnée doit être manipulée comme un fichier, plus le modèle fichier est pertinent ; plus elle doit être consommée comme un volume brut à très faible latence, plus le bloc prend l’avantage ; plus elle doit passer à l’échelle et s’automatiser, plus l’objet devient intéressant.
Dans les faits, un réseau mal pensé bloque plus vite que le disque lui-même. Un simple lien trop lent, un switch surchargé ou une topologie sans redondance peut transformer un bon support en goulot d’étranglement. C’est pour cela que je ne sépare jamais architecture de stockage et architecture réseau.
Une fois le réseau compris, il devient plus facile d’aligner l’architecture sur l’usage réel.
Comment choisir la bonne architecture selon l’usage
Je préfère raisonner par scénario plutôt que par technologie. C’est plus concret, et cela évite les achats “généraux” qui finissent trop chers ou trop limités.
| Usage | Architecture la plus cohérente | Pourquoi | À éviter |
|---|---|---|---|
| Bureautique et documents partagés | NAS avec snapshots et sauvegarde externalisée | Simple à administrer, collaboration fluide, bonne lisibilité des fichiers | Distribuer les fichiers sur des postes locaux sans politique de sauvegarde |
| Bases de données et machines virtuelles | Stockage bloc sur SSD, avec redondance et réplication | Faible latence, meilleures IOPS, comportement prévisible sous charge | Un partage de fichiers générique sans garantie de performance |
| Photos, vidéos, journaux applicatifs, datasets | Stockage objet ou hybride avec cache local | Très bonne scalabilité, métadonnées utiles, automatisation facile | Tout conserver en haute performance alors que la majorité des accès sont rares |
| Archivage légal ou historique | Archive froide, bande ou tiering objet à coût réduit | Moins cher sur la durée, mieux adapté aux données peu consultées | Conserver indéfiniment sur la couche la plus rapide et la plus coûteuse |
| Mobilité et accès distant | Synchronisation sécurisée, accès cloud contrôlé, partage sélectif | Pratique pour les équipes distribuées et les usages multi-appareils | Ouvrir un stockage interne sans règles d’accès ou sans authentification forte |
En 2026, je conseille souvent une approche hybride : la donnée active reste proche des applications, tandis que les copies de secours et les archives partent vers une couche moins coûteuse et mieux isolée. Ce découpage évite d’encombrer l’infrastructure primaire avec des fichiers qui ne servent presque jamais.
C’est ce croisement entre usage, performance et niveau de risque qui fait le bon arbitrage.
Sécurité, sauvegarde et conformité à ne pas traiter séparément
Je considère la sécurité comme une partie intégrante du stockage, pas comme une surcouche optionnelle. La règle la plus utile reste la 3-2-1 : 3 copies des données, sur 2 supports différents, dont 1 hors ligne ou isolée. Quand la disponibilité devient critique, j’ajoute souvent une réplication sur un second site, parce qu’un seul emplacement physique reste une faiblesse structurelle.
- Chiffrement : il protège les données au repos et pendant le transport, surtout si l’environnement est hybride ou distant.
- Contrôle des accès : droits minimaux, MFA et séparation des rôles réduisent les erreurs humaines et les usages abusifs.
- Journalisation : les logs permettent de détecter les suppressions anormales, les connexions inhabituelles et les tentatives de contournement.
- Snapshots et copies immuables : très utiles contre les erreurs de manipulation et les ransomwares.
- Tests de restauration : une sauvegarde non testée est une hypothèse, pas une preuve.
Sur les données personnelles, la conformité impose de définir une durée de conservation et un mode d’archivage. La CNIL distingue une base active, un archivage intermédiaire et, si nécessaire, un archivage définitif. Cette logique est utile même hors cadre juridique strict : elle force à séparer ce qui doit rester disponible de ce qui doit seulement être conservé.
À mes yeux, c’est là que beaucoup de projets se fragilisent : ils investissent dans un bon support, mais sans politique de conservation, de suppression et de restauration. Le matériel est prêt, pas l’exploitation.
Et c’est justement là que les erreurs de départ coûtent le plus cher.
Les erreurs qui font exploser les coûts ou les risques
| Erreur fréquente | Conséquence | Correction que je recommande |
|---|---|---|
| Confondre redondance et sauvegarde | Une panne ou une suppression se propage quand même | Garder une copie indépendante, idéalement hors ligne ou immuable |
| Tout laisser sur la couche la plus rapide | Coût inutilement élevé et architecture difficile à faire évoluer | Réserver le SSD aux accès fréquents et déplacer le reste vers des tiers moins chers |
| Ignorer la bande passante réseau | Les utilisateurs perçoivent le stockage comme “lent” alors que le vrai problème est le réseau | Mesurer le débit réel, la latence et les pics de charge avant de déployer |
| Ne pas définir de durée de conservation | Accumulation de données inutiles, risque juridique et coûts croissants | Écrire une politique de conservation simple, par type de donnée et par finalité |
| Ne jamais tester les restaurations | Découverte tardive d’une sauvegarde inutilisable | Planifier des tests réguliers sur un échantillon représentatif |
| Sous-estimer les coûts d’exploitation cloud | Stockage bon marché en apparence, mais facture plus lourde à la sortie ou à la consultation | Chiffrer aussi les accès, les transferts, les sorties de données et les besoins de rétention |
Je vois souvent le même biais : on achète pour “contenir” les données du moment, alors qu’il faut surtout acheter pour les faire vivre dans le temps. Le vrai sujet n’est pas le volume initial, c’est la manière dont il va évoluer, se recopier, se vérifier et se réduire.
Quand ces points sont verrouillés, la stratégie reste simple à maintenir.
La combinaison qui fonctionne le mieux pour la plupart des équipes
Si je devais proposer un socle raisonnable pour la plupart des organisations, je partirais sur une logique en quatre couches : des données actives sur un support rapide, des fichiers partagés sur un NAS ou un service équivalent, des sauvegardes isolées et un archivage séparé pour tout ce qui n’a pas besoin d’être réouvert souvent. C’est sobre, compréhensible et bien plus durable qu’une architecture monolithique.
- Conserver les données chaudes sur SSD ou sur un stockage bloc bien dimensionné.
- Mettre les documents de travail sur une couche fichier claire et facile à administrer.
- Déporter les archives et les gros volumes peu consultés vers l’objet ou la bande.
- Externaliser au moins une copie de secours, avec une vraie politique de restauration.
- Réviser régulièrement les durées de conservation et les droits d’accès.
La règle qui me guide le plus reste finalement assez simple : ne jamais laisser la criticité, la durée de vie et la fréquence d’accès des données dicter le même niveau de stockage. Quand on sépare correctement ces paramètres, on réduit les coûts, on gagne en fiabilité et on évite les mauvaises surprises au moment où il faut restaurer vite et bien.